How We Built Aanshbot: A Practical Technical Deep Dive
This is the technical companion to our executive launch post. For the strategic narrative, read Aanshbot: Turning Discovery Conversations Into Decision Intelligence.
Product Requirements That Drove the Architecture
Aanshbot was built around one product goal: improve the next discovery question using corpus evidence while enforcing role-based privacy by default.
Five requirements shaped the implementation:
- Responses must follow a strict coaching contract, not generic Q&A.
- Internal and external users should use one app with different evidence visibility.
- Retrieval must be grounded in curated corpus evidence.
- Safety controls must handle redaction and leakage automatically.
- The system must ship quickly on managed infrastructure with clear boundaries.
The resulting design is retrieval-first, schema-constrained, and role-aware.
Stack and Service Boundaries
Current stack:
- Next.js App Router + TypeScript (UI and API routes)
- Supabase (Auth, Postgres, pgvector, RLS)
- OpenAI (generation + embeddings)
- Vercel-ready deployment model
In practice, this is one Next.js app with route groups for intake, chat, analysis, planning, evidence exploration, playbooks, feedback, ingestion, and version diffs.
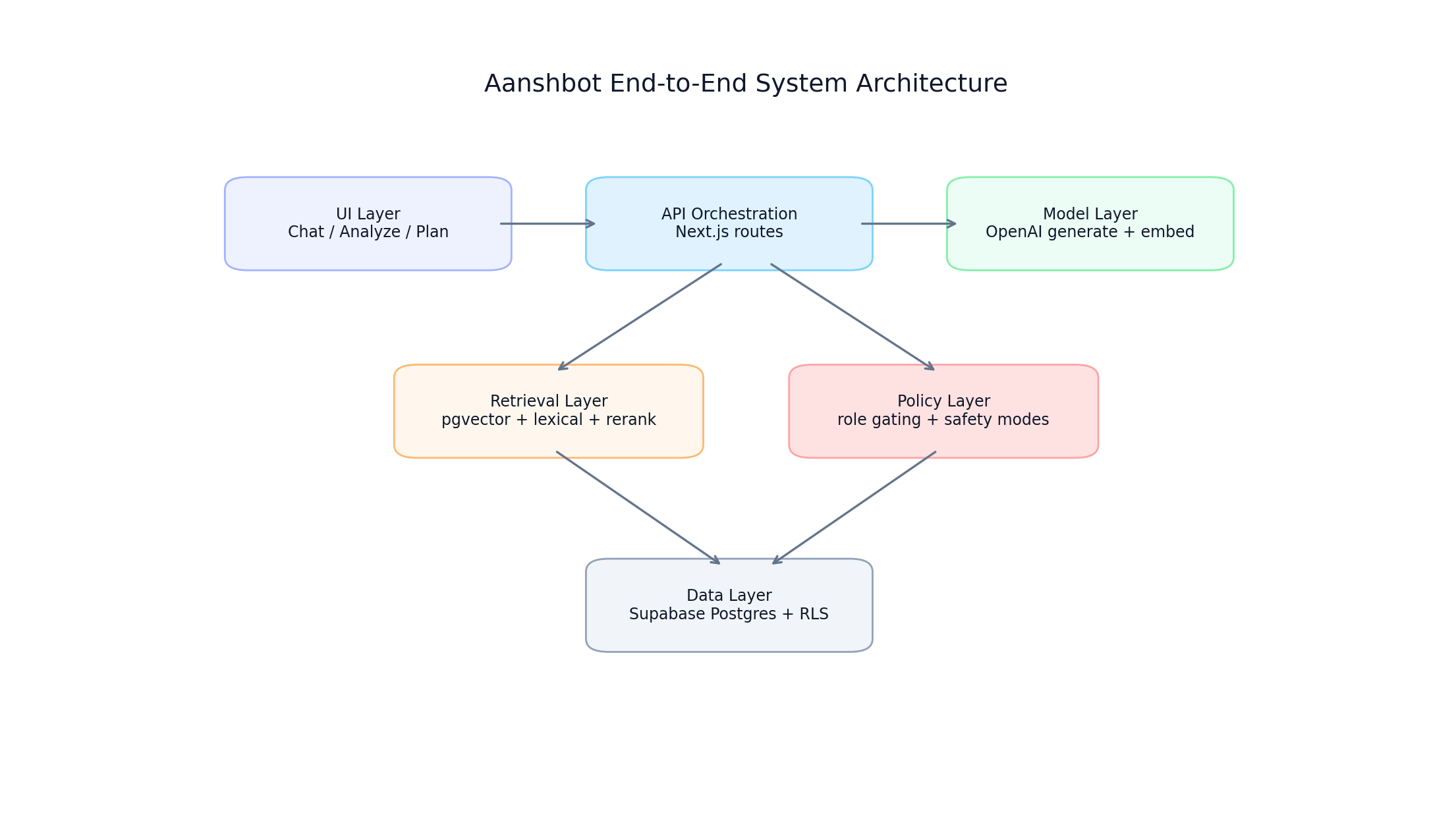 Aanshbot system architecture across app, data, model, and policy layers
Aanshbot system architecture across app, data, model, and policy layers
FIGURE 1: Layered system architecture for Aanshbot across interface, orchestration, retrieval, and safety layers.
Data Model and Access Posture
The data model is centered on session context, evidence lineage, and traceable outputs.
Core entities include users, sessions, documents, chunks, evidence refs, messages, feedback, playbooks, and document diffs.
Two implementation choices are critical:
- Generated responses are traceable to chunk-level evidence.
- Evidence has role-specific display tags for internal vs external rendering.
RLS is enabled broadly. User-owned session/message/feedback/playbook flows remain accessible, while corpus and quota-sensitive tables are protected behind server-side access paths.
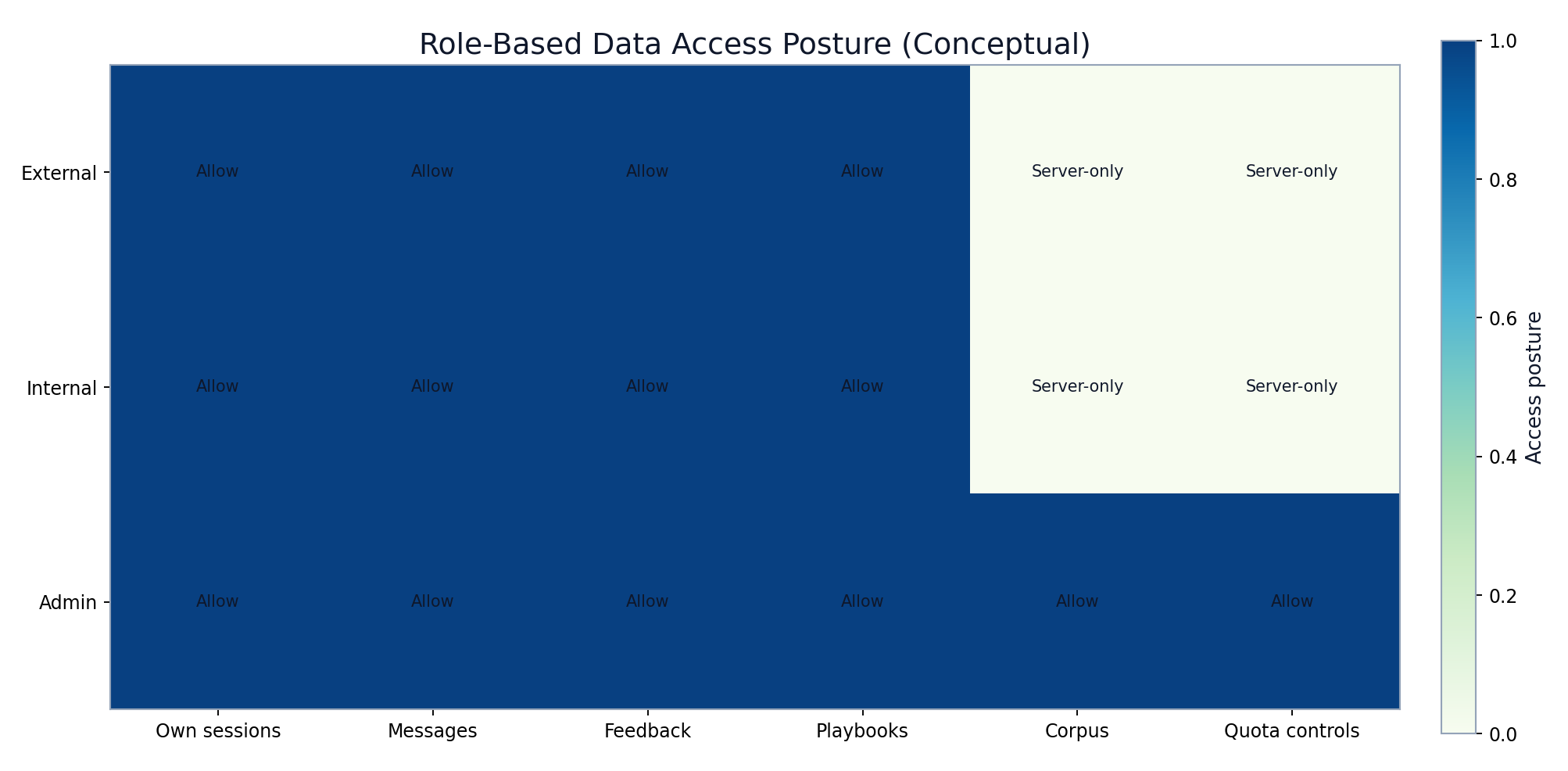 Role-aware data access and RLS posture map
Role-aware data access and RLS posture map
FIGURE 2: Role-safe access posture showing user-owned paths versus protected corpus and control tables.
Ingestion Pipeline and Corpus Versioning
Ingestion accepts multiple source formats and normalizes them into retrieval-ready chunks.
Pipeline:
- Parse file content into normalized text.
- Build structured blocks (interview sections when available).
- Chunk into semantic segments with metadata.
- Generate embeddings (
text-embedding-3-smalldefault). - Insert chunks and evidence references.
- Switch active corpus version.
- Compute and store version-diff summary when prior version exists.
Current implementation note: active-version switching uses a two-step flow, not a single transactional swap.
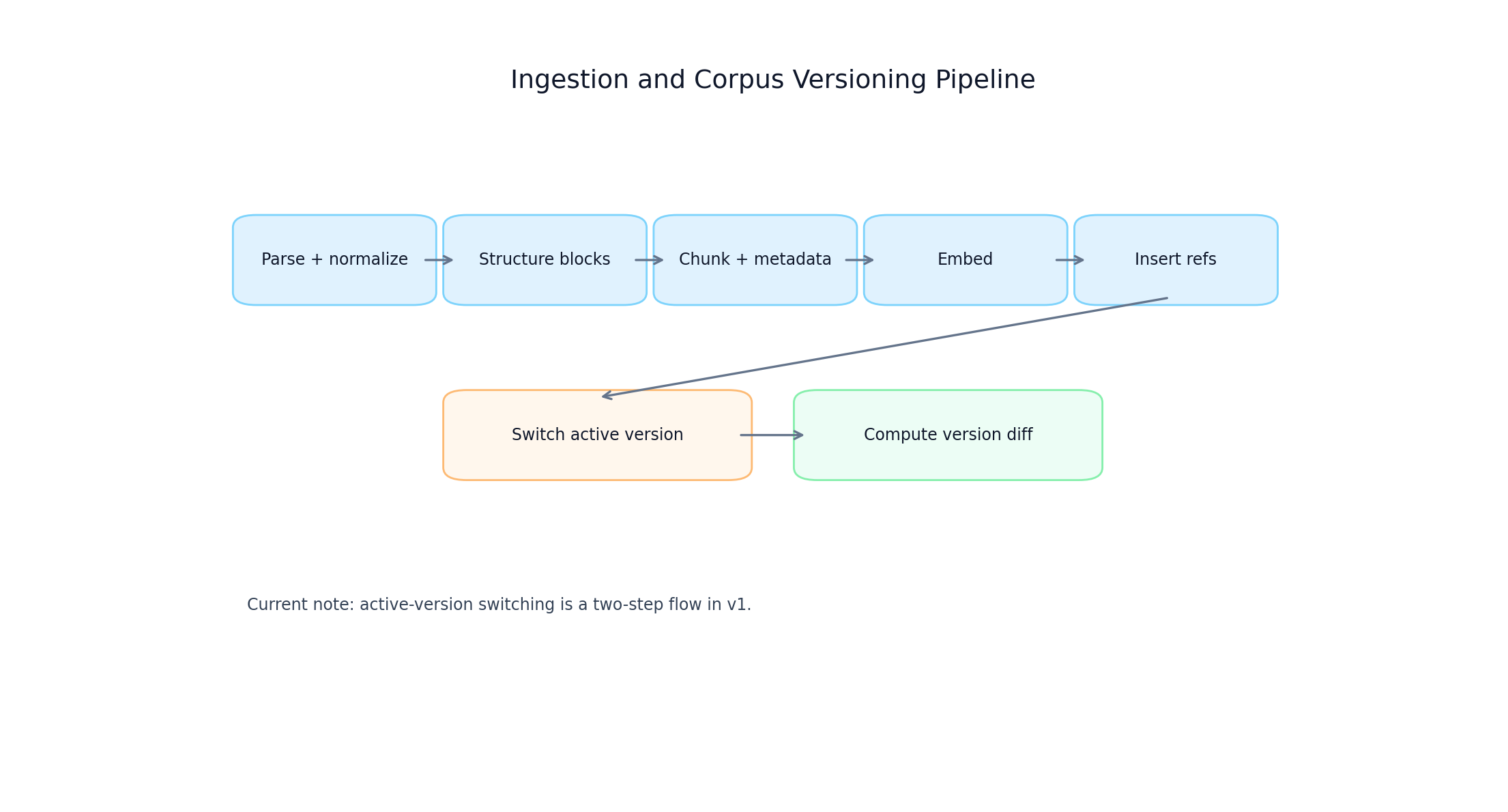 Ingestion and corpus versioning pipeline
Ingestion and corpus versioning pipeline
FIGURE 3: Ingestion-to-activation flow, including chunk generation, evidence refs, and version diff creation.
Hybrid Retrieval and App-Layer Reranking
Retrieval combines SQL-level hybrid scoring with app-level reranking under latency budget controls.
Core blend formula:
hybrid_score = semantic_score * 0.82 + keyword_score * 0.18
SQL phase handles semantic + lexical matching over active corpus only. App phase improves continuity and ranking quality for multi-turn interview coaching.
1def retrieve_ranked_evidence(query, conversation_context, budget_ms):
2 retrieval_query = build_query(query, conversation_context)
3
4 primary = sql_hybrid_search(retrieval_query, top_k=24)
5 candidates = primary
6
7 if weak_or_sparse(primary) and time_remaining(budget_ms):
8 rescue = keyword_rescue_search(retrieval_query, top_k=12)
9 candidates = merge_unique(primary, rescue)
10
11 ranked = rerank_with_features(
12 candidates,
13 lexical_overlap=True,
14 recency=True,
15 diversity_penalty="mmr_style",
16 )
17
18 return ranked[:8]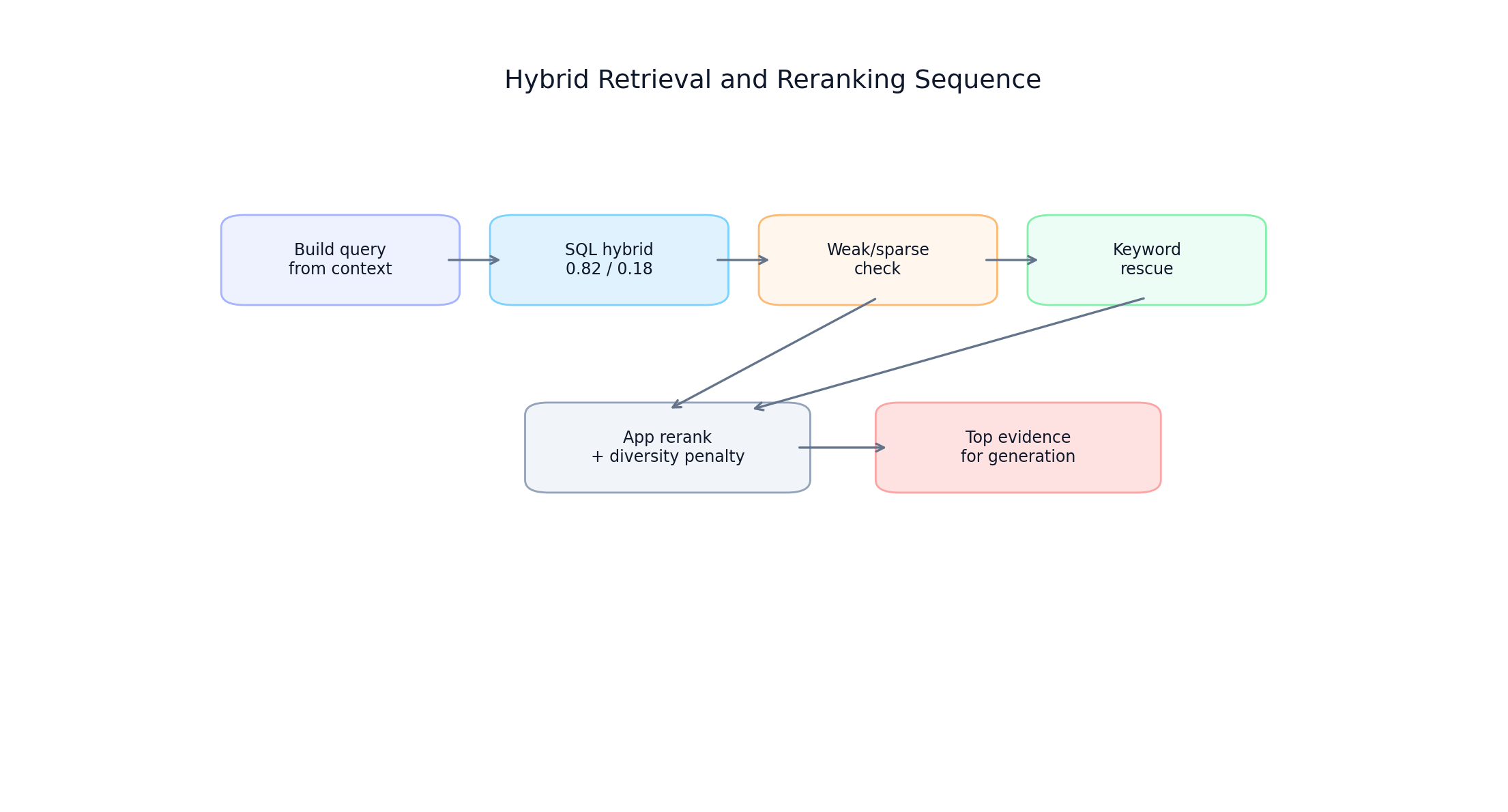 Hybrid retrieval and reranking sequence
Hybrid retrieval and reranking sequence
FIGURE 4: Retrieval sequence from hybrid search through rescue and reranking for final evidence selection.
Generation Contract and Schema Enforcement
Generation is prompt-constrained, JSON-only, and schema-validated.
Model routing:
- Primary:
gpt-4.1-mini - Fallback:
gpt-4o-mini - Verifier default:
gpt-4o-mini
Output contract requires exactly three buckets (problem, workflow, risk) and required fields per question.
1class Question(BaseModel):
2 main: str
3 rephrased: str
4 why_it_matters: str
5 what_to_listen_for: str
6 confidence: float
7
8class ResponseContract(BaseModel):
9 synthesis: str
10 problem: list[Question]
11 workflow: list[Question]
12 risk: list[Question]
13 follow_up_paths: list[str]
14
15
16def normalize_contract(payload):
17 parsed = ResponseContract.model_validate(payload)
18 ensure_exact_three_buckets(parsed)
19 return fill_safe_defaults(parsed)Verifier Gate and Repair Strategy
A verifier stage is triggered when output quality/grounding/confidence risk crosses threshold inside a bounded latency budget.
Repair strategy has two levels:
- Deterministic bucket repairs (fast path)
- Optional model rewrite for only failing questions (time-budget permitting)
1def maybe_repair_output(contract, quality, grounding, confidence, budget_ms):
2 if not should_verify(quality, grounding, confidence):
3 return contract
4
5 repaired = deterministic_repair(contract)
6
7 if still_failing(repaired) and time_remaining(budget_ms):
8 repaired = targeted_model_rewrite(repaired, failing_buckets_only=True)
9
10 return repaired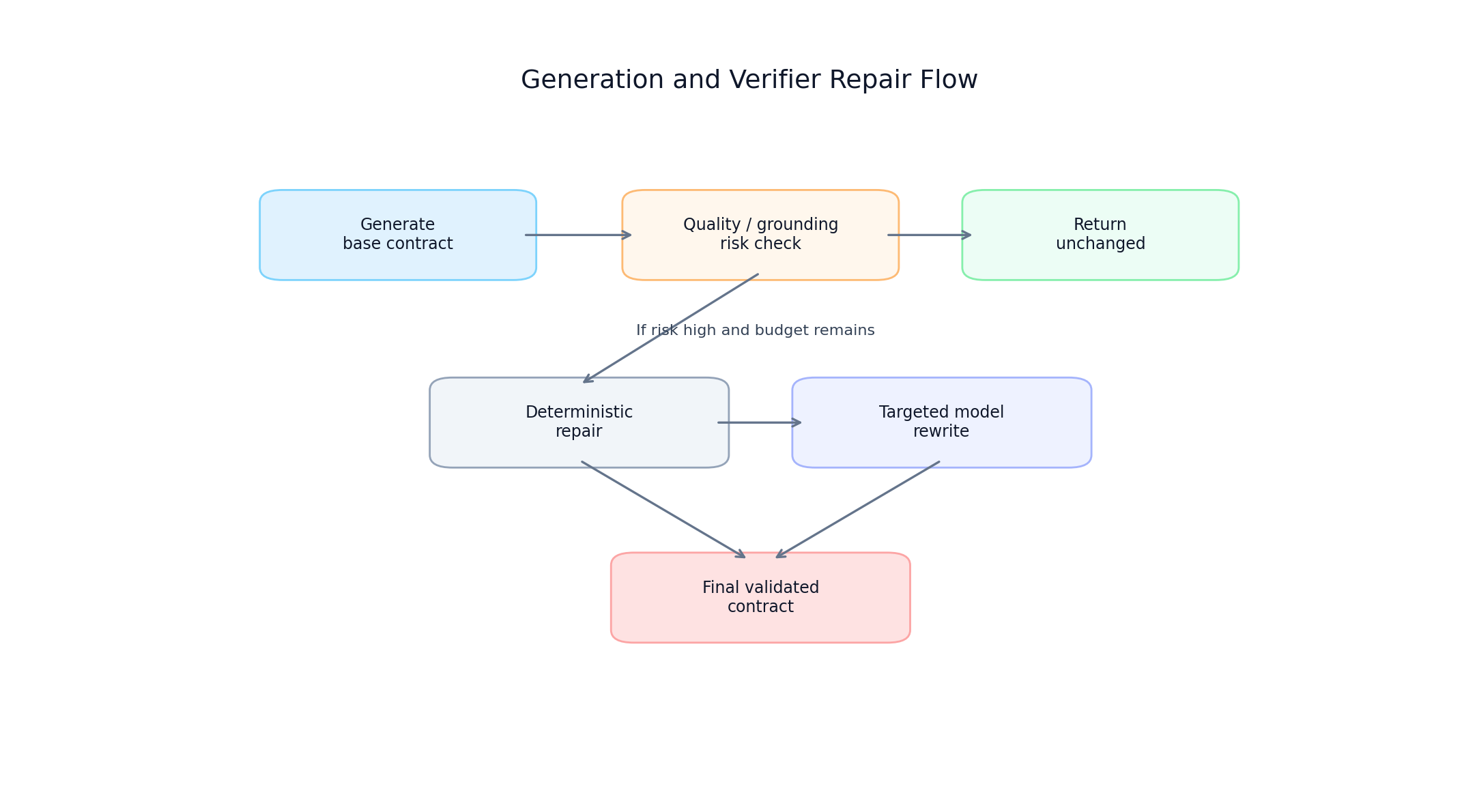 Generation plus verifier decision flow
Generation plus verifier decision flow
FIGURE 5: Verifier-gated repair flow balancing quality recovery with strict response-time budgets.
Safety Modes and Redaction Loop
Safety is role-aware and enforced in layered stages:
- Role policy in generation prompts
- External-mode redaction transforms
- Leakage detection on generated output
- Stricter regeneration when required
- Safe fallback coaching when leakage persists
Implemented safety states:
internal_namedexternal_redactedexternal_regeneratedexternal_fallback
1def safe_external_response(draft, sensitive_terms):
2 redacted = redact_external(draft, sensitive_terms)
3 if not leaks(redacted):
4 return redacted, "external_redacted"
5
6 regenerated = regenerate_strict(redacted)
7 if not leaks(regenerated):
8 return regenerated, "external_regenerated"
9
10 return fallback_coaching(), "external_fallback"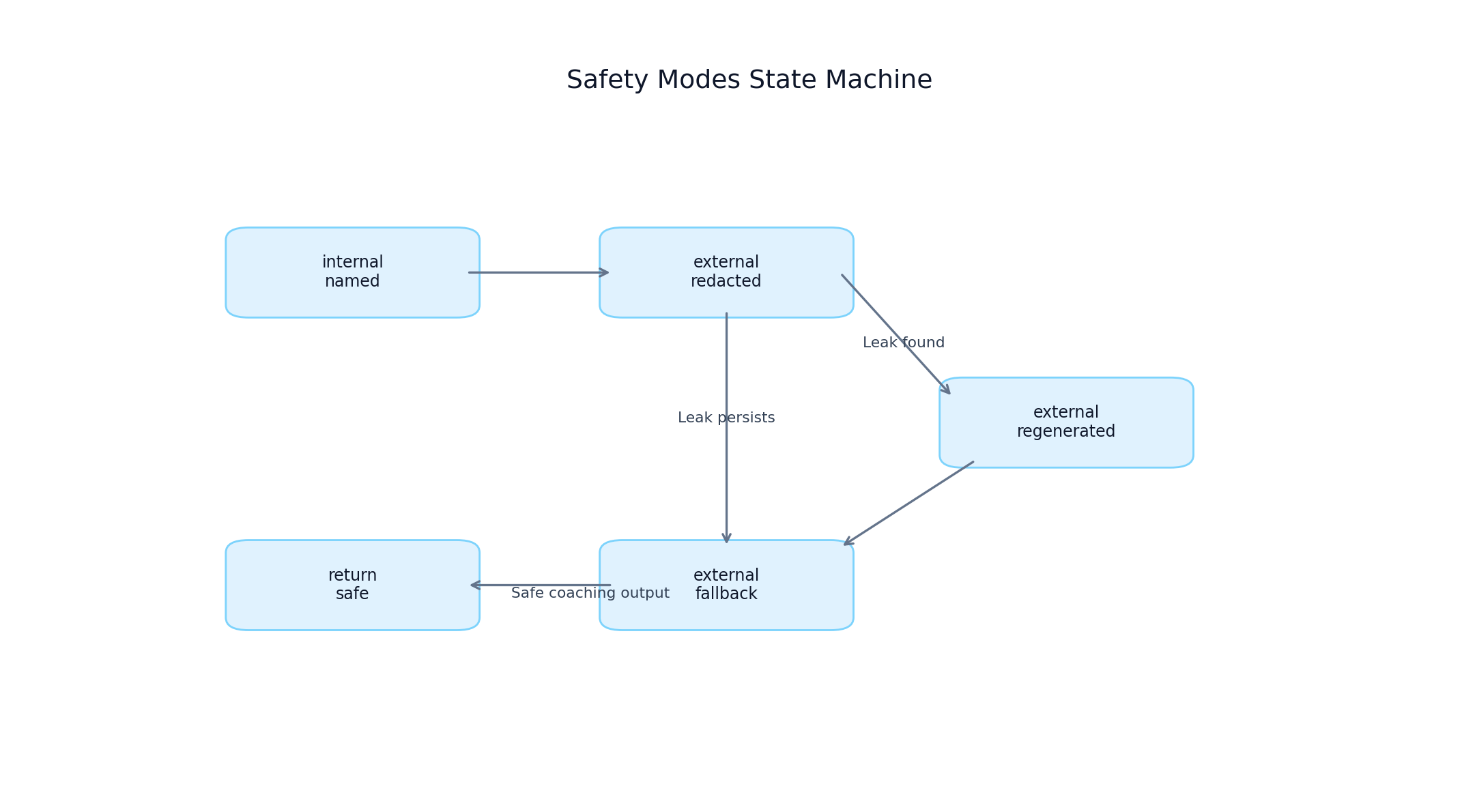 Safety mode state machine for internal and external responses
Safety mode state machine for internal and external responses
FIGURE 6: Safety state transitions for redaction, regeneration, and fallback protection.
Shared Feature Modules (Analyze, Plan, Playbooks, Explorer)
Aanshbot keeps advanced features on the same retrieval and policy stack:
- Answer Analyzer
- Interview Plan mode
- Question quality scoring (specificity, leading strength, decision relevance)
- Contradiction detection by theme
- Confidence meter from retrieval strength, diversity, and recency
- Saved playbooks
- Version diffs
- Evidence explorer filters
This avoids fragmented prompt islands and keeps behavior consistent across workflows.
Auth Reliability and Quota Controls
Auth reliability was hardened around three areas:
- Redirect base resolution across configured base URL, forwarded origin, and host fallback.
- Session callback handling for both token-hash and code exchange paths.
- Quota/rate pathways that convert provider limits into clear user-facing retry guidance.
1def resolve_auth_redirect_base(configured_base, request):
2 if configured_base:
3 return configured_base
4 if request.forwarded_origin:
5 return request.forwarded_origin
6 return request.host_originExact threshold values and anti-abuse tuning are intentionally omitted from this public write-up.
Observability and Learning Loop
Two primary outcome signals are persisted:
usefulness_score(1-5)used_question(boolean)
Structured assistant payloads are also stored to support later analysis by mode and context.
Confidence meter skeleton:
confidence = w_r * retrieval + w_d * diversity + w_c * recency
Production weights are internal and tuned over time.
 Product learning loop from usage to feedback to prompt and playbook updates
Product learning loop from usage to feedback to prompt and playbook updates
FIGURE 7: Learning loop from conversation usage signals to retrieval/prompt/playbook refinements (illustrative).
Tradeoffs and Current Boundaries
Current scope is intentionally narrow:
- Curated manual ingestion (no auto transcript sync in v1)
- Single active corpus retrieval path
- Strict output contract over open-ended generative flexibility
- Managed infrastructure speed over custom infra complexity
That constraint set kept the system deployable for real discovery workflows while preserving a clean foundation for deeper evaluation and analytics.
To see the product experience that this architecture supports, visit askaansh.briefcaseai.org.
Related Reading
- Aanshbot: Turning Discovery Conversations Into Decision Intelligence
- Multi-Agent Orchestration: Building Parallel Coordination Systems
- The Escalation Tax
Want fewer escalations? See a live trace.
See Briefcase on your stack
Reduce escalations: Catch issues before they hit production with comprehensive observability
Auditability & replay: Complete trace capture for debugging and compliance